 Preview Post
Preview Post
- March 24, 2026

Backlinks still sit at the heart of SEO. That much we can all agree on. They remain one of the strongest signals in Google’s ranking system, and we spend a lot of time chasing them, auditing them, and benchmarking them. But here is something I don’t hear talked about very often: what if the page that holds the backlink is not even in Google’s index anymore? Can it really pass anything of value?
This is me thinking out loud. I’m not claiming any facts. But looking at the evidence does seem to lean a certain way, and I think it is worth exploring.
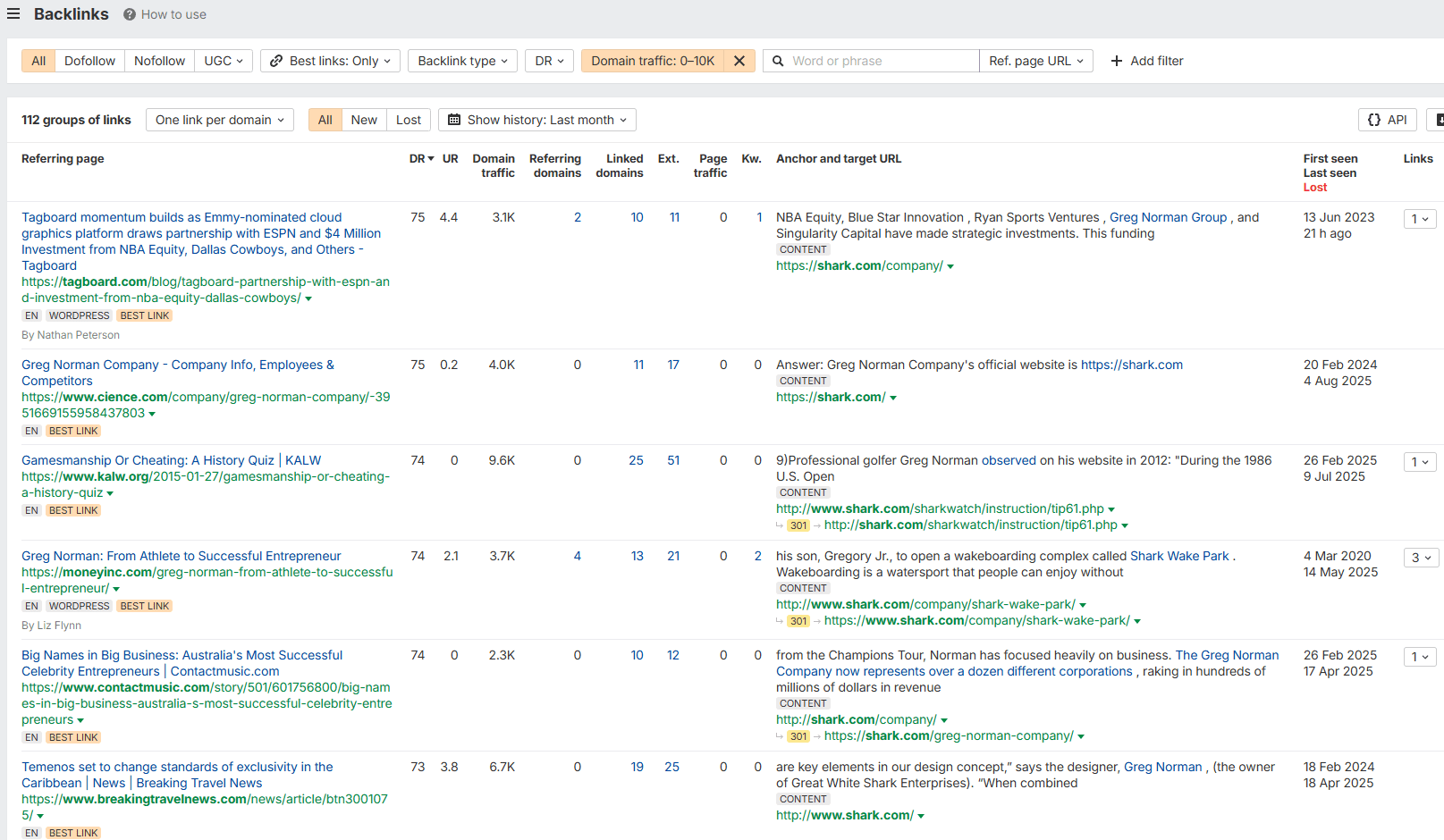
Most conversations I hear in SEO circles are still about dofollow versus nofollow, anchor text, redirect behaviour, noindex, topical relevance, and, more recently, vector embeddings. And of course, we spend a lot of time talking about metrics like Domain Rating (Ahrefs DR), Domain Authority (Moz), or Authority Score (Semrush). These are useful as proxies, but they all share the same blind spot. They measure what their crawlers see, not what Google keeps in its index.
Let me give a quick example. Say a site has a DR of 55. It has 1500 referring domains and over 30,000 backlinks. That looks strong on a Google Sheets comparison chart. But how many of those backlinks actually sit on old blog posts, product pages, or syndicated news articles that Google dropped years ago? Ahrefs will still count them in your DR. Google might not.
In the last year or two, we’ve all seen it. Index coverage reports in Search Console are dropping like a stone. Established sites are losing thousands, sometimes millions, of indexed URLs. News articles, evergreen blog posts, forum threads, you name it. They used to sit quietly in the index and now they are gone.
This is not a handful of pages we are talking about, either. This is billions and billions of URLs across the web. Google has become far more selective about what it chooses to keep. Duplicate content, thin content, low engagement, “unhelpful” pages. The helpful content update, the core updates, and the push towards quality signals. It all points in the same direction.
So if Google is removing so much content from its index, what does that mean for backlinks placed on those pages? Can a link from a page Google has already deemed not worth indexing still pass authority? My gut says probably not.
We do know some facts. If a page 404s, it passes no PageRank. That is clear. If a page is blocked from crawling, then Google cannot see its content or links. That is also clear.
But what about the grey zone? Pages marked as “Crawled – currently not indexed” in Search Console. Pages that are discovered but never indexed. Pages that are duplicated and dropped in favour of a canonical one. These situations are less clear, but it seems logical that if a page is not indexed, then Google does not think it is useful. And if it is not useful enough to keep, why would Google let it transfer value through its outbound links?
I find myself leaning towards the idea that such links are either heavily devalued or ignored altogether. I cannot prove that. Nobody can outside of Google. But the behaviour of the index suggests that is where the evidence points.
At this point, it helps to bring in an expert view. Adam Gent, Co-Founder of Indexing Insight, summed it up to me recently:
“General rule of thumb is that only links from indexed pages are used in page quality calculations (which uses Nearest Seed PageRank). But there are some use cases that get complicated.”
— Adam Gent, Co-Founder of Indexing Insight
This is where the gap opens up. Tools like Ahrefs, Moz, and Semrush are counting every link their bots crawl. They are not making editorial decisions about what deserves to stay in an index. They are just counting links.
So your DR 55 profile might be built on a lot of links that, in Google’s eyes, no longer exist in a meaningful way. That goes some way to explaining why a site with strong third-party metrics can sometimes underperform in organic search.
It also helps explain the frustration many site owners feel. They see their site with DR 55 and 30,000 backlinks losing ground to a competitor with DA 25 and only a few hundred referring domains. On paper it makes no sense. But if half your backlinks are sitting on URLs that Google dropped years ago, then the numbers in Ahrefs are misleading you.
This is where it gets interesting. When a newer DA 25 site is outperforming your 10-year-old DR 55 site, the usual finger points to tech SEO issues or content relevance. And yes, those can be major factors. But what if part of the answer lies in how many backlinks are actually still indexed?
Imagine two sites. One has 30,000 backlinks, but only 40 percent of them sit on indexed pages. The other has 2,000 backlinks, but 90 percent are on indexed pages. Which one is Google likely to reward?
I have to admit, I don’t hear people asking this question in strategy sessions, LinkedIn, or conference talks. Yet it seems like one of the most basic realities we should be considering.

Here is the catch. We cannot easily know. Ahrefs does not show whether the backlink source page is indexed in Google. Neither does Semrush or Moz. The only way to check would be to run large-scale scraping or API checks against Google to see which of your backlinks are actually still in the index. That is not cheap, quick, or simple. It requires investment and effort.
That is why this part of the puzzle rarely gets explored. It is much easier to accept DR, DA, or Authority Score at face value and move on. But if we want to truly understand the gap between what tools say and what Google rewards, I think this is one of the places we need to look.
I want to be clear here. I am not presenting this as a fact. Google has never stood up and said “pages that are not indexed cannot pass PageRank”. But when you connect the dots, it feels like the evidence leans in that direction.
The logic is simple enough. If Google chooses not to keep a page in its index, deindexing it, then it clearly does not see it as valuable to users. And if it is not valuable to users, why should its links be valuable to rankings?
Backlinks still matter. No doubt about it. But not all backlinks are equal. The industry spends a lot of time talking about follow versus nofollow, anchor text, topical relevance, link velocity. I am starting to think that indexation status of the source page deserves a place in that list.
If so many pages are being dropped from Google’s index, then we should at least consider the possibility that some of our prized backlinks are not worth as much as our tools suggest. It is not a comfortable thought, but it might help explain why there is often such a gap between third-party metrics and actual ranking performance.
I will keep asking myself these questions, and I think more of us should, too. How many of our backlinks are actually indexed? How many of our competitors’ backlinks are indexed? If we do not know the answer, are we really seeing the full picture?
That is where my head goes. I might be wrong on all this. But it is worth thinking about.
I put a post out on LinkedIn asking this very question, and it did seem to resonate. There were plenty of comments. Here are some of the best:
“If a page isn’t (or is no longer) in Google’s index, we must question why that is.
One thing we often overlook as SEOs is the fact that the main purpose of links is to be navigational and take a user from Page A to Page B. As an industry, we often seem to have forgotten that and focus only on ‘the SEO benefit’ of links.
If a page isn’t indexed, there’s going to be a reason why that’s the case. If that’s because Google has chosen not to index that page (or has dropped it from its index), it’s a quality issue. Would we really expect to benefit from a link on that page? I don’t think so.
If a link is on a page that’s got a noindex tag, for example, it’s a little more complicated, but my point still remains … there’s a reason why that page isn’t available for indexing, so is the link actually valuable? Maybe sometimes, often not.”
— James Brockbank, SEO & Digital PR Consultant
“If you noindex a page, the links stop mattering. So I can’t see why this would be any different, following the same logic.”
— Mark Williams-Cook, SEO Consultant
“I also think pages with higher traffic have more value to send to their links, so a page with zero traffic gives zero value to its links.”
— Matthew Taylor, Founder of Kidsit.com
“If a link is not in the index – I’d like to think that the majority of the time, the equity of the link and therefore the value that we as SEOs would be after would be stripped.
I think it also depends on why that page is not in the index. Is it setup with a noindex tag? Or is Google crawling the URL but choosing not to index the URL. I think if this was the case then there’s potential Google could pass some form of value on.
Based on this, I do also think it’s possible that the page may not be in the index but may still be crawled – so I think it’s possible a page could still be discovered via a link that wasn’t indexed.
That’s of course a very rare and unlikely scenario though that Google would choose to continue to actively crawl a page but not index it.”
— Harrison Lemon, Tech SEO Account Director





Comments:
Comments are closed.