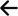 Preview Post
Preview Post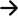
- March 24, 2026


A lot of people picture ChatGPT sending one simple query to a search provider and then building an answer from whatever comes back. It is not quite that straightforward. The process under the hood is much closer to a small search engine working inside the model, taking your prompt, branching it into several intent variations, checking multiple data sources and then pulling everything together before it even starts writing.
I am still learning how all of this fits together myself, and I enjoy sharing what I pick up along the way so other SEOs can follow the same journey. The more we understand how these systems fetch and interpret information, the better we can position our content for what comes next.
• ChatGPT does not run one query. It expands your prompt into several intent variations.
• Each variation is sent to multiple licensed search providers and APIs.
• Only the top slice of results from each provider is taken.
• All results are merged using Reciprocal Rank Fusion, which rewards agreement.
• Pages that appear highly across several sources rise to the top.
• Only a small shortlist is selected and used as the actual citations.
• The model reads those shortlisted pages and writes the final answer.
• If ChatGPT cites your site, it usually means you performed well across multiple retrieval feeds.
So the workflow is essentially:
Handful of QFOs → top slice of results from each → RRF ranking → top few sources → answer.
Image Credit: Jérôme Salomon (LinkedIn post he wrote)
When you send ChatGPT a question, it does not just fire that exact wording at a single search provider. Instead, it expands your prompt into a small cluster of alternative queries (Query Fan Out – QFO). Each variation captures a slightly different way of expressing the same intent, which gives the system wider coverage without veering off into irrelevant territory.
The idea is simple. If one phrasing misses useful information, another one should pick it up. It is a bit like running several internal site search queries for the same user question. You are widening the net just enough to improve recall, while keeping everything tightly aligned with what the user actually wants.
I asked ChatGPT How many QFOs are generated?
Typically several. It is rarely just one, and it is not hundreds either.
Think of it as a small cluster of alternative query formulations covering:
• different phrasings
• different scopes
• different intent angles
• sometimes different time sensitivities
Enough to widen coverage, but not enough to cause noise.
It is closer to a handful rather than dozens.
Once those QFO queries are generated, ChatGPT sends each one out to several licensed search providers and APIs. This is not a single-feed situation. It pulls from a mix of general web search sources and more specialised data providers, which gives it a broader and more reliable view of what is out there.
Crucially, it only takes the top slice of results from each source. The system is not trawling through hundreds of URLs or crawling anything in depth. It relies on the assumption that the strongest and most relevant pages will appear near the top, and it filters out the long tail entirely. This keeps the process fast, clean and far more robust than most people expect.
This is where everything gets pulled together. Once all the sources have returned their top results, ChatGPT drops them into a single pot and runs a fusion method called Reciprocal Rank Fusion (RRF). Think of it as a lightweight ranking algorithm that rewards consensus. If the same page appears across multiple providers, especially near the top of each list, the system pushes it up rapidly.
Pages that only appear once, or that sit halfway down a single feed, barely move the needle. They are recorded, but they have no real influence because they do not show cross-source strength. The whole point is to identify the URLs that consistently look good wherever you check. It is surprisingly similar to an SEO tool aggregating keyword rankings from several data partners, then highlighting what they all agree on.
From an SEO perspective, this is the closest thing to a ranking stage inside the LLM retrieval pipeline. It is fast, simple and brutally effective.
Once the fusion step is complete, the model now has a merged list ordered by strength. But it does not use all of it. Only a very small shortlist makes the cut. These are the pages that become the official citations you see in the final output. They are the sources the model actually reads and relies on.
Anything outside the shortlist is not thrown away. It remains in the wider context pool, so the model can review it if needed. But those pages do not meaningfully shape the answer. If you are trying to win LLM citations, this is the moment where you either get picked or you do not.
It is the same idea as a crawler pulling in thousands of URLs, but only sending a select few pages for full rendering and indexing.
Only after all of that groundwork does ChatGPT start writing. It reads the selected pages directly, extracts the useful bits and turns them into a coherent answer. The citations you see are not decorative. They point back to the exact sources that shaped that response.
This is why LLM citations feel more trustworthy than simple scraping. The system is not hallucinating links. It is showing you a handful of sources that genuinely influenced the answer. For SEOs, this means your content is not just being seen, it is playing an active role in the output if you make it into that shortlist.
This whole workflow clears up a lot of the confusion we have seen recently around LLM visibility. When ChatGPT goes off to fetch live data, it behaves more like a mini search engine than a simple API caller, which has a few big implications for us.
If several providers index the same article, that page becomes far more visible to LLMs because the fusion stage rewards agreement. The more places your content appears in the top slice of results, the more likely ChatGPT is to surface it.
Pages that rank well across multiple search APIs also benefit. Consistency matters here. If you only rank well in one source but drop off in others, you are far less likely to be selected. Weak or niche results never survive the fusion process because they show up once, low down, and get buried.
So when an LLM cites your site, it is not random. It usually means your page performs strongly across several retrieval feeds. In other words, the model has seen your content appear repeatedly at the top of its merged list.
This also explains why some people assumed ChatGPT was pulling directly from Google. If SERP API or another partner uses Google data as part of their feed, and your page ranks highly there, the result looks the same from the outside. The system is not hitting Google directly, but the inputs can still overlap, which is why the behaviour can feel very similar.





Comments:
Comments are closed.