 Preview Post
Preview Post
- March 24, 2026

There’s a growing discussion in SEO and AI circles about a small but potentially important text file: llms.txt.
On the surface, it looks familiar. Like robots.txt, it’s a flat text file placed in the root directory of your website. But where robots.txt tells search engines what not to crawl, llms.txt is written for an entirely different audience: large language models.
Jeremy Howard, co-founder of Answer.AI, introduced the idea in late 2024. The format is markdown-based. The purpose is clarity. It exists to help LLMs better understand the structure and purpose of your content, without relying on them to parse complex HTML, dynamic JavaScript, or bloated layouts.
If you’re already thinking “that sounds speculative,” you’re not alone. The SEO community is split. Some see potential. Others see a solution looking for a problem.
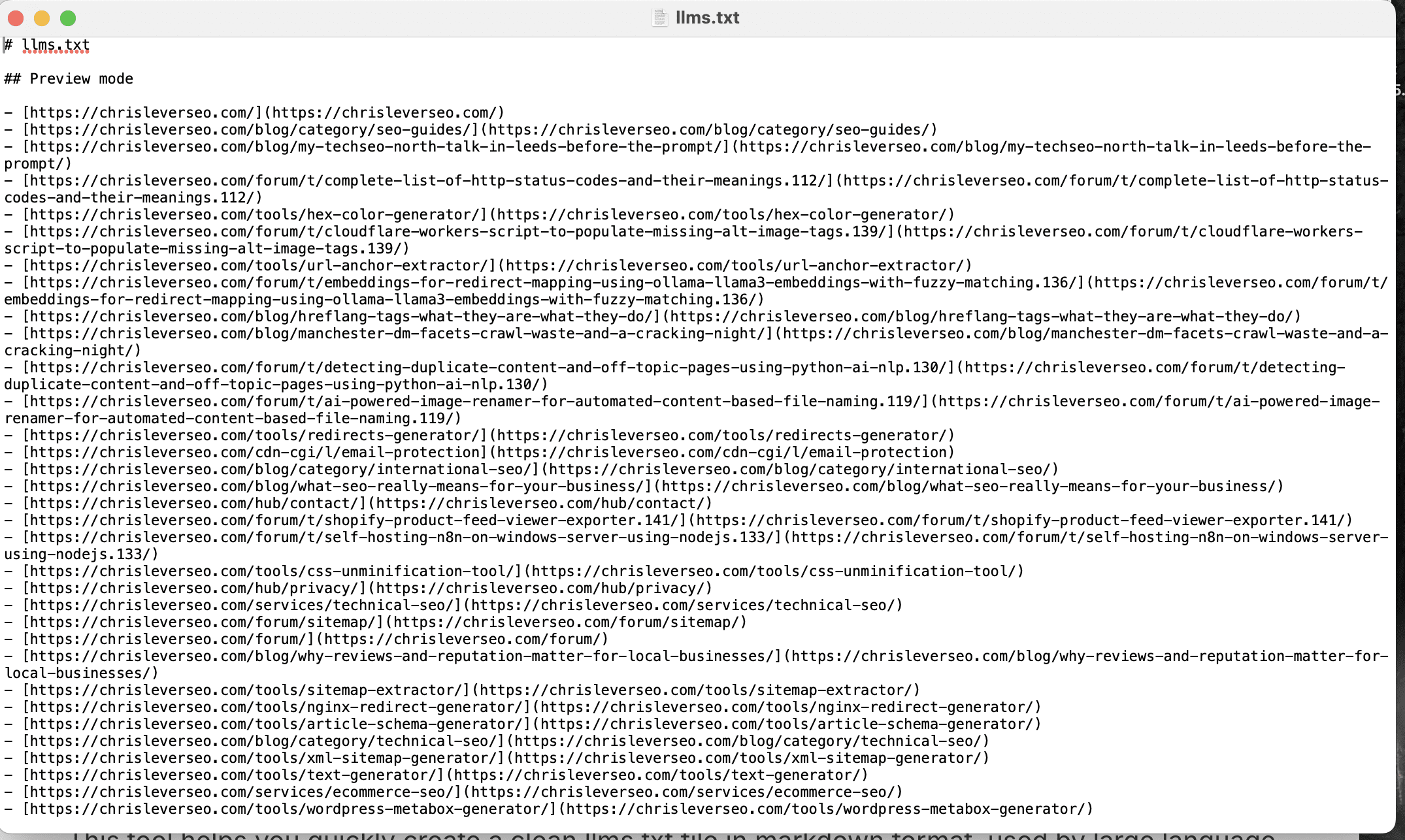
At its core, llms.txt is a structured file designed to help AI models understand your website more easily.
It doesn’t block crawlers. It doesn’t enforce behaviour. It simply offers a human and machine-readable guide to the key parts of your site, typically broken down into:
Here’s a basic example:
1 2 3 4 5 6 7 | # llms.txt ## Docs- /api.mdSummary of API methods, rate limits, and authentication ## Policies- /returns.html Our return policy and processing timelines ## Products- /sizing-guide.phpSize charts for all product categories |
It’s simple. It’s clean. And it allows an LLM or agent to jump straight into meaningful context rather than waste tokens parsing irrelevant parts of your UI.
Some organisations are also adopting llms-full.txt, which is exactly what it sounds like: a flattened version of all your key documentation in a single markdown file.
This file can be hundreds of thousands of tokens long and is often used in environments where Retrieval Augmented Generation (RAG) is in play. It’s particularly useful in developer IDEs like Cursor, Claude Code, or tools like FireCrawl or Mintlify that support direct ingestion of markdown docs.
The benefit? Context-rich AI interaction. The downside? If you’re not managing chunking, context windows or latency, you’re not going to get much from it. And if your content isn’t well written to begin with, more tokens won’t save you.
A growing number of developer-focused companies have adopted the format:
They’re not just experimenting. Some have automated the creation of these files directly from their documentation platforms.
But here’s the catch. There is no formal adoption by OpenAI, Google, Meta or most other major LLM providers. GPTBot doesn’t mention it. Google-Extended doesn’t use it. Claude publishes a file but hasn’t said whether Claude crawls them. That’s a sticking point. Why write a file for crawlers that don’t officially support it?
The reaction among SEOs has ranged from curiosity to cynicism.
Brett Tabke, founder of Pubcon and WebmasterWorld, put it bluntly:
“We just don’t need people thinking LLMs are different from any other spider.”
Others point out the overlap with existing tools. We already have XML sitemaps and use structured data. So why add a new protocol with no industry backing?
But there’s a counter-argument that’s hard to ignore. Just because Google isn’t indexing it doesn’t mean the idea lacks merit.
As SEOs, we’ve been trained to optimise for algorithms. But if those algorithms shift from search to answer generation, then maybe llms.txt is not about visibility now — it’s about preparing for visibility later.
There are no direct ranking boosts. No traffic surges. No confirmed integration from major LLM providers.
But there are still tangible use cases:
Tools like Codeium and Cursor let users load documentation directly from a URL. If your llms-full.txt is formatted well, you’re giving these tools exactly what they need in one file.
If you’re building your own LLM-powered tools, chatbots or help assistants, a well-maintained llms.txt and llms-full.txt file gives you a ready-to-query documentation source.
Flattening your site into a single file forces you to see it as a whole, which is valuable in content design, taxonomy review, keyword clustering, and entity analysis.
If LLMs ever do start supporting it officially, you’re already ahead. You’ve structured your site in a way that machines can consume without needing to reverse-engineer your layout.
Here’s where I stand.
If you’re running a large e-commerce site, the ROI is probably negligible, at least for now. There are bigger fires to put out. But if you own developer-facing documentation, product specs, complex onboarding flows, or training materials, you’re already writing content for humans and machines. This is a low-effort addition.
Even if the format never gains universal adoption, creating an llms.txt file forces you to think about your content structure in a new way. That’s never wasted time.
There’s also a risk if this becomes another SEO arms race. We’ve seen this before with keyword stuffing, link directories, blog comment spam, and structured data abuse. llms.txt opens the door to similar manipulation — flooding the file with keywords, brand mentions, or contrived entities.
Also, by making your site easier to scrape, you’re lowering the barrier for competitors to analyse your site. That’s not a new problem, but it’s worth noting. A 150,000-word llms-full.txt file is a gift to anyone doing programmatic analysis.
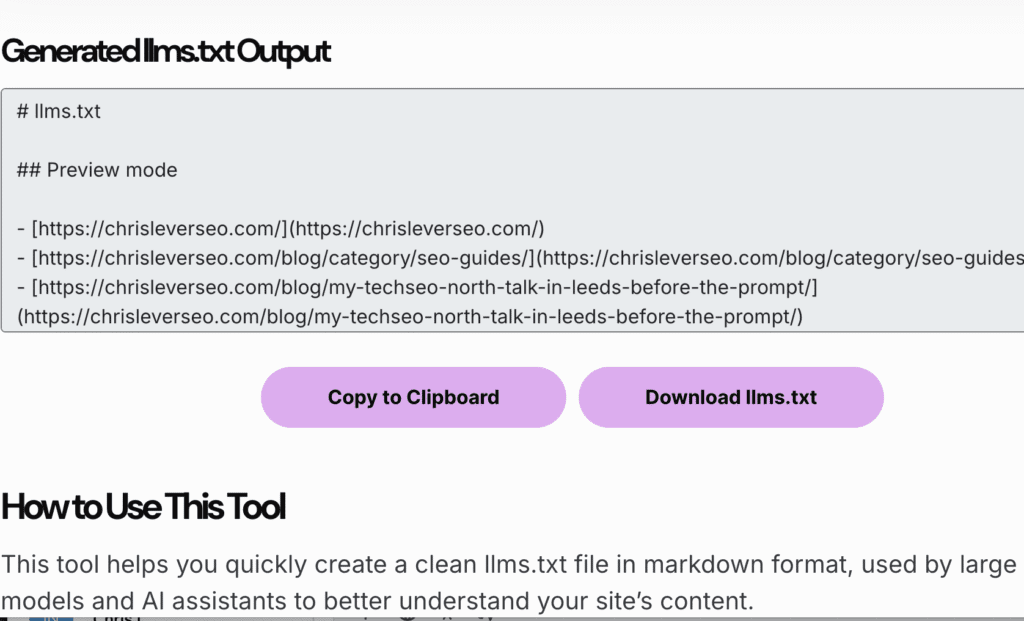
I’ve been following the discussion for a couple of months. So I built a free tool for the community.
You can now generate a clean, structured llms.txt file directly from a pasted list of URLs or build it manually with section labels and summaries. You can export the result, copy it, or use it in your internal projects.
I don’t think llms.txt is a silver bullet. But I do think it signals something important.
It’s a glimpse of how content might be indexed and consumed in an AI-native world. Where search doesn’t send ten blue links, it sends a single generated answer. Where documentation isn’t read line by line, but queried contextually by a model that knows what to skip.
You want your site to be part of that answer.
So, if you’ve got the time, write your llms.txt, clean up your documentation, and help the machines a little. Whether it pays off now or later is part of the bet we’re all making.
Try the llms.txt Generator





Comments:
Comments are closed.