 Preview Post
Preview Post- March 24, 2026

There is a big difference between understanding how search works in theory and having to deal with it in practice.
For a long time I have worked around search engines and websites, auditing them, reverse engineering behaviour, and trying to influence outcomes. At some point that naturally turns into a different question. What happens if you stop working around them and try to build one yourself from the ground up?
That is what SolvedSeek became. SolvedSeek is a Search Engine that I built as a side project.
The whole point was to own the entire stack. Crawling the web directly, building an index from scratch, deciding what gets stored and what gets ignored, and then layering ranking and semantic understanding on top of that. No external APIs, no shortcuts, just a full pipeline running on infrastructure I control.
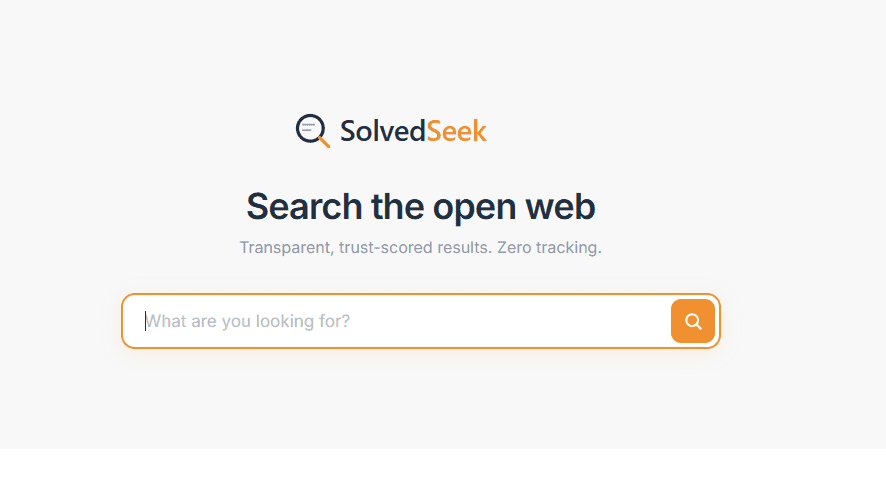
You can crawl pages, render JavaScript where needed, extract content, build signals, generate embeddings, and return ranked results that feel coherent. You can get to a point where it behaves like a real search engine rather than a toy project. That is the satisfying bit. Everything connects, queries return something sensible, and for a moment it feels like you have cracked it.
That feeling does not last very long. Believe me!

Very quickly it stops feeling like a system and starts feeling like a game of whack a mole. You fix one issue and another pops up somewhere else.
You stabilise memory usage, then hit a batch of pages that blow your heap anyway. You tweak your crawler behaviour, then run into a set of sites that behave completely differently to everything else you have seen.
JavaScript heavy websites are a constant one. You think you are crawling content, then realise you are crawling shells of pages with nothing in them. So you introduce rendering. That works, until it slows everything down and creates a queue you now need to manage.
Indexing signals are another one. On paper they are straightforward. In practice they conflict all the time. Canonical says one thing, meta robots says another, headers add something else again. You end up writing logic to decide which version of the truth you believe.
Then you run into WAFs and CDNs. Pages that technically load, but not in a way your crawler can use. Challenge pages, partial responses, or content that never actually resolves. You are not just crawling websites at that point, you are trying to work around infrastructure designed to stop you.
Spam never really goes away either. You filter one pattern and another appears. Not always obvious junk, but content that is just good enough to get through if your thresholds are not tight. So now you are constantly tuning quality scores, trust signals, and thresholds just to keep the index usable.
It becomes less about building something once and more about constantly reacting to what the web throws at you next.
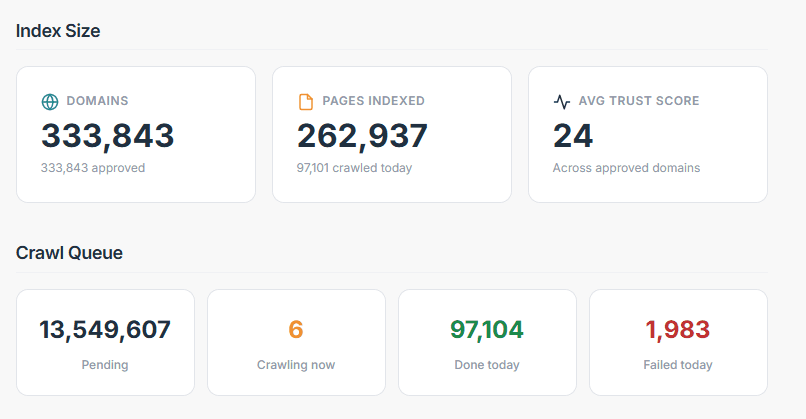
One of the bigger takeaways is that search is only as strong as its weakest layer.
Crawling feeds the index. The index feeds ranking. Ranking relies on the quality of the extracted content. Semantic understanding relies on everything before it being clean enough to work with.
When something breaks, it does not stay isolated. If your crawler struggles, your index quality drops. If your extraction is off, your ranking signals become unreliable. If your filtering is too loose, spam creeps in. If it is too strict, you lose good content.
Everything is connected, which means every fix has side effects somewhere else. Which brings you back to the whack a mole problem again. It eats up too much time and energy.
This is the point where the project shifted for me. The most valuable part of SolvedSeek is not the search interface or even the ranking layer. It is the crawling and processing pipeline behind it.
A system that can reliably discover pages, respect crawl rules, handle rendering, deal with messy signals, and extract usable content from the modern web is useful in its own right.
I have decided to pull back on the idea of pushing this as a full search engine. Not because it did not work. It does. But because I have proved what I set out to prove.
I wanted to know whether I could build a real, independent search engine from scratch, with full control over crawling, indexing and ranking. I can, and I did.
What comes after that is a different commitment. Running a search engine is not a one off build. It is continuous maintenance against a web that does not sit still. For me, the more sensible move now is to take the part that is genuinely strong and apply it in a more focused way.
This project has changed how I see the web.
From the outside it looks structured and predictable. Up close it is messy, inconsistent, and full of edge cases that only show up when you have to deal with them at scale.
Building something that has to process all of that forces a different level of understanding.
And it also makes one thing very clear. You can build a search engine. Keeping it clean, stable and useful is where the real hard work starts.
SolvedSeek is a Search Engine that I built as a side project. Feel free to visit: https://solvedseek.com





Comments:
Comments are closed.