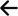 Preview Post
Preview Post
- March 24, 2026

I’ve been thinking about Model Context Protocol (MCP) and what it could mean for technical SEO monitoring and support.
An MCP server is a core part of the Model Context Protocol, an new open standard that lets AI models access and interact with external tools and data. In SEO, it could act as a bridge between the AI model and your real-world tech stack: crawl data, server logs, sitemaps, and change history. It allows AI to work with actual context, not just prompts. That’s the shift from isolated analysis to live integration with the systems that drive your site.
Most technical SEO work and tools today are stateless. We run a crawl, raise tickets, report back on fixes, and then walk away. A few months later, we do it again, often from scratch. What changed? Was the last fix deployed? Was it rolled back? Did a rule get overridden by another team? What was the rationale behind that redirect pattern or that decision to exclude a path from indexing? In nearly every case, we’re relying on memory, scattered documentation, or reverse-engineering to figure it out. It’s reactive and brittle, and it gets worse the more complex the site becomes.
An MCP server might be able to change all of that. It gives you a way to create, store, and query structured context persistently across time. You’re not just dumping notes into a wiki or writing comments in a Jira ticket. You’re defining stateful knowledge: facts, rules, strategic intents, decisions, exceptions, and relationships. And you’re making that knowledge machine-readable and queriable by models, agents, or your own tools. That’s a foundational upgrade to how we do technical SEO, and it opens up real operational possibilities.
The first and most obvious application is building persistent memory across audits. Today, when we crawl a site, we treat it as a moment in time. We export data, generate insights, and create recommendations. But when we crawl again, we don’t have structured recall of the previous audit. What changed? What stayed the same? What didn’t get fixed? What regressed? What new risks were introduced as part of other fixes?
An MCP server could store contextual memory objects for each crawl. That includes the data itself, but also annotations, comments, known workarounds, and strategic explanations. You’re no longer re-learning the site each time. You’re interacting with a versioned knowledge layer that grows and adapts as the site evolves. It doesn’t forget why something was done or who decided it. It holds that knowledge in context.
This is especially powerful in large organisations where technical decisions are made by multiple teams. When your SEO agent or audit process accesses the MCP server, it sees the same context every time. It remembers historical fixes, past indexing issues, previously excluded templates, and what happened the last time someone rewired the nav or changed the product schema.
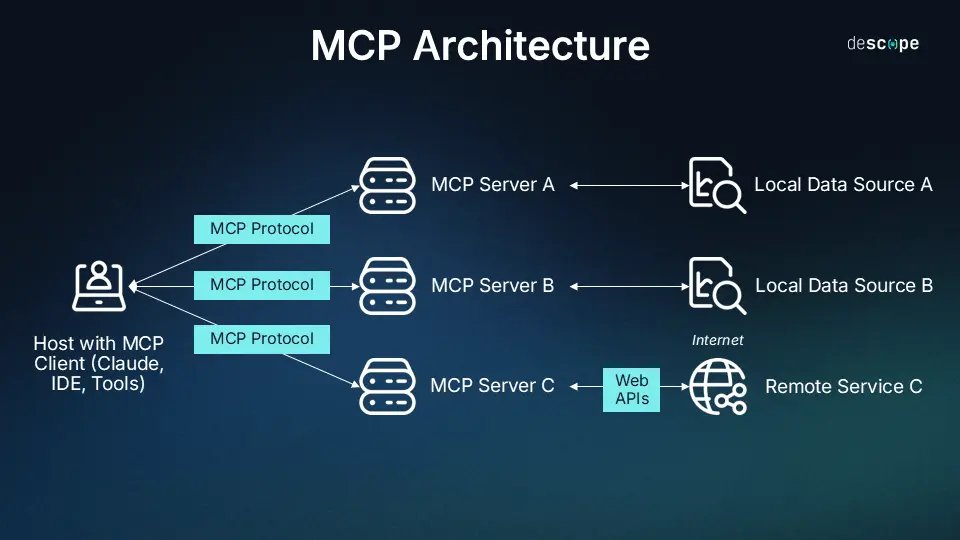
Image Credit: https://www.descope.com/
This is where the real future begins. Everyone’s talking about AI agents in SEO. Most of it is hype. But the real bottleneck isn’t the intelligence of the model, it’s the lack of structured memory (think RAG, but better and realtime). Prompting ChatGPT to “audit a site” is meaningless if the model doesn’t remember how your specific platform works, what SEO strategies you’re using, and what the constraints are.
An MCP server acts as the context engine for that agent. You don’t prompt from zero every time. You assign the agent to an SEO memory stack. That stack contains everything the agent needs to operate intelligently on your site: how your faceted navigation is configured, which templates use hreflang and why, which areas of the site are indexable and which are suppressed due to legacy issues or regional differences. The agent doesn’t guess. It queries.
This makes technical SEO far more intelligent. The agent isn’t auditing by default rules, it’s auditing against your specific rule set. It’s not flagging “duplicate content” based on shallow heuristics, it’s cross-referencing past decisions and known exceptions. You end up with fewer false positives and a more strategic response. The agent becomes a collaborator, not just a checklist generator.
Every technical SEO decision is a trade-off. But most of those trade-offs are lost after implementation. Why was that folder blocked? Why is that category excluded from internal linking? Why did we shift canonical logic for variant products in that one template only? The intent behind the rule is more important than the rule itself, but it rarely gets preserved.
With MCP, intent becomes part of the context. You don’t just say “we’re canonicalising all product pages to the base SKU,” you attach the reason: “to consolidate authority and simplify indexing after discovering Google was indexing param variants with inconsistent reviews data.” That’s stored in context. It’s available to your agents, to new team members, to external consultants, to yourself six months from now when someone starts questioning it. And when that canonical rule breaks due to a new deployment, the system understands the significance, because it understands the intent.
Crawlers are efficient at fetching pages and recording metadata. They are terrible at applying learned context across runs. They don’t know what changed unless you manually compare exports. They don’t prioritise based on strategic significance. They don’t remember which parts of the site are volatile and which are stable. And they don’t differentiate between a regression and a new issue.
Imagine wiring a crawler to an SEO MCP server. The crawler queries context before initiating a run. It sees what changed recently. It knows which templates are high-risk. It understands that a canonical bug was just fixed last week and should be validated again. It compares current state to historical context and flags mismatches with meaning. Instead of showing you a list of broken pages, it tells you which problems are new, which ones have re-emerged, and which fixes are still holding. That’s not just smarter crawling, it’s crawling with memory and strategy baked in.
Search Console provides basic indexing reports, but it doesn’t preserve state across time in a useful way. You can’t ask it what was excluded last quarter and why. You can’t link indexation drops to template changes or sitemap structure shifts unless you manually piece it together.
An SEO MCP server can log and track indexation state as part of the broader context model. You can represent each URL or template as a contextual entity: what it is, what it’s for, where it lives, what its intended indexation behaviour is, and what has historically occurred. You can query indexation coverage not just as a raw percentage, but as a time-series comparison against expected behaviour. You can filter to show only unexpected changes or mismatches between intent and outcome. And you can tie those changes to deployments, content migrations, or template rollouts.
This makes indexation management less about triage and more about governance. You stop treating it as a report and start treating it as a living system state that can be queried, monitored, and acted upon.
Most SEO knowledge today is local and fragile. It lives in one person’s brain or scattered across old decks and buried tickets. When people leave or projects shift, that knowledge decays. You get duplicate efforts, conflicting logic, and strategy drift.
MCP could offer us a model for collaborative SEO knowledge graphs. Instead of writing docs, you write structured context. Each part of the site, each template, taxonomy, redirect pattern, crawl policy is defined and annotated in context. That context is queryable by models, accessible by agents, and updateable by humans. It becomes part of the infrastructure. And it persists across time, roles, and tools.
That’s what most SEO teams are missing. Not just more automation, but better memory. Not just faster tools, but smarter systems that remember what was done and why.
The SEO industry is starting to realise that prompting GPT with raw HTML and asking it to do an audit is gimmicky. You get shallow output, obvious suggestions, and no sense of site-specific nuance. The answer isn’t better prompts. It’s persistent context. When the model has access to long-term structured knowledge about your site, its answers become strategic instead of generic. That’s the difference between noise and signal.
I’m not claiming to have this fully implemented. But I’m exploring it seriously. And I’m starting to design around it. Because if you’ve ever had to explain the same SEO rule to five different teams, or re-justify a decision you made a year ago because the rationale is lost, you already know the value of a system that remembers.
This is not about replacing humans. It’s about extending our memory and enforcing the strategic coherence we keep losing between audits, sprints, and stakeholder churn. MCP offers a protocol-level framework for that. And technical SEO is overdue for that kind of upgrade. Personally I think this is a concept worth exploring and something I’m going to dedicated some time to building and testing. Who know’s you might see me again at BrightonSEO next year talking about SEO MCP Servers. If you’re building around this or exploring it, I’d love to talk. Comment on my LinkedIn post, lets chat: https://www.linkedin.com/posts/chris-lever-seo_techseo-mcpserver-experiment-activity-7324088320571977730-9lVi





Comments:
Comments are closed.